How consensus and data availability impact decentralized scalability of blockchains
Overview of Avalanche's Snowball Consensus and Celestia's Data Availability Sampling

Abstract
Aiming to understand the design decisions of Avalanche and Celestia networks, we study here the sources associated with the two projects and present it in a review form. After brief introduction and defining the problem of blockchain scaling, we summarize the properties of most commonly used Nakamoto and Tendermint consensus protocols and follow it with discussion of Avalanche Consensus. The second part considers another approach to decentralized scaling initiated by Celestia that focuses on fighting state growth with modular Data Availability Sampling. We conclude by briefly summarizing the similarities and differences between the two discussed solutions.
1. Introduction
Designing a distributed computing system is always about trade-offs. The holy grail for blockchains is to scale their performance (higher throughput and lower latency), while keeping them secure (safe against double spending attacks and resistant to denial of service attacks) and importantly, decentralized (scalable to high numbers of participants and permissionless to join and leave). Various approaches have been proposed since the creation of Bitcoin to improve on its design. While the solutions presented in production till now introduce improvements in some parts of the blockchain trillema vertices (Security, Decentralization, Scalability), they usually weaken some other. Increasingly novel designs aim to sacrifice the least of security and decentralization while scaling to higher throughputs.
Two of these competing designs are Avalanche and Celestia, each choosing different approach to scaling while preserving decentralization. The differences have sparked multiple debates between the developers of each chain, discussing fundamental properties of solutions they are working on. As a relative newcomer to the crypto space, I couldn’t follow these discussions in enough detail to understand the different aspects considered, while the two sides were often strongly polarized. In my view, the core debate boiled down to two general questions that each team is trying to answer:
is data availability an important parameter of blockchain design?
is consensus protocol a major hurdle in blockchain scalability?
Trying to answer these questions for myself, I decided to set as an incentive the goal of writing a review article, gathering answers from various sources and presenting arguments for both. The text below is the result of that effort, which I refined compared to my notes, so that the broader part of crypto community that wishes to understand these blockchain design solutions could learn more easily. The list of sources on which the article is based on is presented at the end, which can also be used to expand in more detail on different topics mentioned here.
First, we start with some general definitions of scaling and what parameters can be scaled in a blockchain. The following is then split into two parts, in the first one we discuss consensus algorithms starting with the basics, explaining how the most popular Nakamoto and Tendermint consensus work, and then following with description of Avalanche Consensus and possibility of scaling the network to large numbers of nodes while preserving fast time to finality thanks to its construction. The second part covers the problem of blockchain state growth and the notion of Data Availability (DA). After defining the problem, we summarize the technique for limiting node state growth - Data Availability Sampling (DAS), that is a major part of Celestia's design leading to its decentralized scalability. Finally, I shortly mention other modular blockchain approaches that aim to compete or coexist with Celestia. The article ends with short summary and conclusion.
While the two discussed approaches are not in direct competition and may seem unrelated, they both present their chosen strategies for scaling where decentralization is the priority. In both cases this is achieved through a sampling-based approach, where each node gains a probabilistic certainity about the state. Therefore, both the aim, allowing many nodes to participate to drive decentralization, and the solution, sampling-based probabilistic certainty are common between these blockchains. The biggest practical difference on the other hand is that Avalanche is trying to keep the full node validator set decentralized, while Celestia introduces a kind of light node that contributes to decentralization of the whole network even when block production itself is centralized.
2. Scaling
In a centralized database system, the solution for scaling is simple, we can just add more servers to handle transactions, and thus increase the computational power. On a blockchain, where every node needs to process and validate every transaction, it would require us to upgrade each node for the network to get faster, the cost of which might get too high for the average node operator. Decentralized scaling of blockchains can be then defined as throughput divided by cost to verify that throughput, meaning that we achieve scaling if we increase the number of transactions per second (tps), but without increasing the cost for the node to verify the chain. Decentralized verification will keep the whole system decentralized even in the case of a centralized prover that could censor transactions, but can never steal the funds.
To better understand the problem of scalability it helps to consider separately the main components of a blockchain:
Data Availability - ensuring the ability to reconstruct the state.
Consensus Protocol - agreeing on the next valid state.
Settlement - enforcing the global state.
Execution - applying the individual state transitions.
The biggest bottleneck for decentralized scalability is considered to be the state growth. As more people use the chain and more transactions occur, the blockchain accumulates the state (information necessary to execute transactions), and it becomes slower and slower to compute over that state, and so, more expensive to run a full node. This creates undesirable situation where the number of full nodes decreases centralizing the network around the consensus nodes.
As a result, public blockchain consensus protocols, often make a tradeoff between low transaction throughput and high degree of centralization. In other words, as the state grows, the requirements for storage, bandwidth, and compute power required to run a full node increases. At some point it may become feasible for only a few nodes to process a block. Blockchains have been created to improve upon the centralized database structure, so we need to keep in mind preserving decentralization aspects while scaling. We would like an average user to be able to run a full node on their consumer hardware. This is why many blockchains are limiting the rate of state growth by enforcing block size and gas limits to keep the cost of generating proofs and syncing the state low.
In order to scale, the blockchain protocol must figure out a mechanism to limit the number of participating nodes needed to validate each transaction, without losing the network’s trust that each transaction is valid. It might sound simple, but it’s technologically very difficult. Generally, light nodes have to work under a much lower security guarantee than full nodes, they always assume that the consensus is honest (correct majority assumption). Full nodes don't have to make this assumption. Contrary to common belief, a malicious consensus e.g. of Ethereum network, could never trick a full node into accepting an invalid block. The honest nodes will notice the invalid transaction and stop following the chain.
High degree of decentralization of block production is one of the main goals for both Proof of Work (PoW) and Proof of Stake (PoS) based consensus protocols. Algorand's random leader election, Avalanche's sub-sampled voting, or Ethereum's 2.0 consensus sharding, are all trying to achieve it in various ways. These design choices prioritize low resource requirements on the block-producing nodes to preserve decentralization of their consensus. While all of them are innovating and pushing this space forward, it’s not evident if in real setting they improve decentralization at all, as at scale stake or hash power end up following a Pareto distribution. This hints for concentrating our efforts to preserve decentralization on block verification rather than production.
Vitalik Buterin considers this vision in his article: Endgame, pondering on various futures for scaling Ethereum, and in each case arriving at the same conclusion:
While there are many paths toward building a scalable and secure long-term blockchain ecosystem, it's looking like they are all building toward very similar futures. (...) We get a chain where block production is centralized, block validation is trustless and highly decentralized, and specialized anti-censorship magic [such as committee validation, data availability sampling and bypass channels] prevents the block producers from censoring [transactions].
3. Consensus
We start with considering consensus design as means for decentralization. It is often misunderstood what the consensus means in the context of blockchain networks. PoW and PoS are confused to be consensus algorithms, while these are strictly Sybil resistance mechanisms and are generally not responsible for reaching consensus.
So what is a consensus algorithm?
It is a protocol for the nodes in a decentralized system to agree on the next valid state of the canonical chain. Moreover, it provides a deterministic or probabilistic guarantee that the ordering of the transactions on the chain will not change (finality), even if a number of nodes in the system is adversarial.
On the other hand, a Sybil resistance means the ability to deter against Sybil attacks.
A Sybil attack is a type of attack on computer network service, in which a single node can flood the network with a large number of pseudonymous identities and use them to gain a disproportionately large influence. Sybil attacks are avoided by requiring a proof of hard-to-forge resource, such as hash power in Bitcoin’s PoW or monetary value at stake and risk of slashing in Ethereum’s 2.0 PoS.
Since in Nakamoto Consensus used in Bitcoin there is no voting and the node presenting the PoW gets to decide on the next state, Bitcoin consensus is often called "Proof of Work" which is not precise. However, Snowball consensus used in Avalanche is paired with Delegated Proof of Stake, but could be used with several other Sybil resistance mechanisms just as well.
3.1 Properties of consensus protocol
Once we have defined what consensus is, we can define two important properties of a consensus protocol to consider: safety and liveness. Safety refers to having a single agreed upon chain. A consensus protocol is considered safe if blocks have settlement finality (which may be probabilistic). Liveness means that the consensus is responsive to new transaction propagation and that valid transactions eventually make it into a block. Depending on the chosen consensus design, we usually get some balance of safety and liveness, but also two other important “macroscopic” properties of blockchain system based on this consensus emerge: latency and throughput.
The first concern of the end user is transaction latency, meaning the amount of time between initiating a transaction and receiving confirmation that it is valid (e.g. confirmation of having enough money in the account). In asynchronous networks, the arrival of transactions is witnessed at varying times among the nodes. For the concurrent processes in a consensus system to agree upon the order in which messages were received, we need to make weak synchrony assumptions, and define a maximum threshold for the latency of network transactions and the speed of processor clocks. In classical Byzantine Fault Tolerant (BFT) systems (e.g. PBFT, Tendermint, Narwhal & Tusk, etc.), a transaction is finalized once it gets confirmed, whereas in longest-chain consensus (e.g. Nakamoto Consensus, Ethereum/Solana PoS), a transaction may get included in a block and then later reorganized. Latency here appears because we need to wait until a transaction is deep enough in the chain for us to believe it is final, and this waiting time is here significantly larger than in single confirmation protocols. Second concern is the throughput, the total load that can be handled by the system per unit of time, expressed in transactions/second.
3.2 Nakamoto Consensus
We start with discussion of probabilistic consensus used by Bitcoin and Ethereum networks. Bitcoin uses Proof of Work system together with the "longest chain" rule, which means that the honest nodes will extend whichever blockchain is the longest. This length is determined by the chain's total cumulative PoW difficulty, and the new block is selected by the first node that solves and presents the PoW. This combination of PoW and longest chain rule is known as Nakamoto Consensus. The security assumption of this model is that over 50% of the hash power is owned by honest nodes. The longest chain is not only deciding the ordering of the sequence of blocks, but also is a proof that the largest pool of computational power generated it. Therefore as long as the majority of hash power is controlled by honest nodes, they will continue to generate the longest chain and eventually outpace the potential attackers. The brilliance of Nakamoto Consensus is economically incentivizing the nodes to expend computational effort and honestly choose the block to be added, by repeatedly performing expensive puzzles for the chance of randomly winning a large block reward.

Ethereum differs from Bitcoin protocol in several aspects, while still (as of publishing date of this article) achieving Sybil resistance through Proof of Work. The blocks are generated every 12-15 seconds which allows for higher throughput, but it also favors transient forks, as miners are more likely to propose new blocks without having heard about the latest mined block. These stale blocks, propagated to the network and verified by some nodes as being correct are eventually cast off as the longer chain achieves dominance. To avoid wasting large mining efforts while resolving forks and to keep the higher throughput, Ethereum uses Greediest Heaviest Observed SubTree (GHOST) as fork selection rule, that accounts for the blocks of discarded branches. In contrast with Bitcoin consensus, GHOST iteratively selects the root of the subtree that contains the largest number of nodes as the successor block. All of the blocks, including the forked ones, contribute to the chain selection. Note that currently Ethereum selects a branch based on the block difficulty without comparing the sizes of the subtrees. GHOST is susceptible to Liveness Attacks, where an attacker with little computation power can stall the consensus, by continually adding forked blocks to two parallel chains and making it difficult to decide which chain is the heaviest.
The Ethereum network will soon undergo The Merge and change its Sybil resistance mechanism to PoS and adopt a new consensus protocol. The first presented provably secure PoS protocols were Snow White and Ouroboros, while Ethereum 2.0 will use a combination of Casper the Friendly Finality Gadget (Casper-FFG) combined with the Latest Message Driven Greediest Heaviest Observed SubTree (LMD GHOST) fork-choice rule, together called Gasper. Gasper is a hybrid between chain-based and BFT-based PoS, as it borrows ideas from both schools of thought and shows provable safety, plausible liveness and probabilistic liveness under different sets of assumptions.
Ethereum 2.0 with its new consensus algorithm, rewards the validators for honestly proposing and validating blocks, while the validators that are absent and fail to act when called upon, miss these rewards and may lose a portion of their stake. For clearly malicious actions validators can be slashed, destroying as much as their whole stake. These mechanisms are put in place to both incentivize honest validators and disincentivize attacks on the network. The plausible liveness achievable by the protocol, is the condition that as long as two-thirds of the total staked ether is honestly following the protocol, the chain will be able to finalize irrespective of any other issues. Gasper also introduces additional line of defense against a liveness failure, known as "inactivity leak" that activates if the chain fails to finalize for more than four epochs. Validators that are not active will have their stake gradually drained away until two-thirds of the validators become active again.
3.3 Tendermint Consensus
After the success of Nakamoto Consensus, deterministic consensus mechanisms have also been proven to work in blockchain environment. This class of Byzantine Fault Tolerant (BFT) algorithms are called classical consensus algorithms. BFT is the ability to tolerate machines failing to follow the protocol in arbitrary ways, including being malicious on purpose. Protocols based on Byzantine agreement typically make use of quorums and require precise knowledge of membership for participation. Practical Byzantine Fault Tolerance (PBFT) requires a quadratic number of message exchanges to reach agreement, whilst having at least 3x+1 total nodes, for x being the Byzantine (malicious) nodes. Tendermint Consensus is modeled as such deterministic protocol, achieving liveness under partial synchrony and throughput within the bounds of the latency of the network and individual process themselves. It is thus a modified version of the Dwork-Lynch-Stockmeyer (DLS) protocol. Developers can use Tendermint for BFT state machine replication of applications written in their chosen programming language and development environment thanks to the Application BlockChain Interface (ABCI) developed by Interchain Foundation.

Tendermint Consensus is a voting algorithm that rotates through block proposers in a stake-weighted round-robin fashion. The stake also proportionally increases the chance to be elected as a leader. Validators take turns proposing blocks and voting on them. If a block fails to be committed, the protocol moves to the next round, and a new validator gets to propose a new block. A block is committed when more than 2/3 of validators pre-commit for the same block in the same round. The commit may fail if the current proposer is offline, who is then skipped, or if the network is too slow. Validators wait a short time to receive a complete block proposal before voting to move to the next round.
The reliance on timeout is what makes Tendermint a weakly synchronous protocol, rather than asynchronous. However, the rest of the protocol is asynchronous and validators only make progress after hearing from supermajority. Assuming less than 1/3 of the validators are Byzantine, Tendermint never forks in the presence of asynchrony, that is it guarantees safety. As a result, Tendermint Consensus-based blockchain will halt momentarily until a supermajority of the validator set comes to consensus.
Block proposer selection in Tendermint Consensus is deterministic, so by knowing the validator set and their voting power distribution, one can know exactly who will be the next block proposer in the following round. It can be argued that this makes Tendermint not decentralized enough, as an attacked could target the validators with a DDoS attack and potentially halt the chain. This kind of attack is mitigated by implementing Sentry Node Architecture (SNA), hiding the IP address of the validator node and providing easily scalable list of public IP addresses for DDoS mitigation. As with many other PoS based protocols, validators risk losing their stake if they are found to misbehave. This defines strong disincentive for incorrect behavior, which can potentially far outweigh any transaction fees or mining rewards gained for correct behavior.
Tendermint has been recently rebranded to Ignite protocol and is used in several leading independent blockchains that make up the Cosmos ecosystem.
3.4 Avalanche Consensus
The challenges in leader selection and management in BFT-based permissionless blockchains have motivated a shift to gossip-based consensus protocols, where a node is only required to know (and send messages to) a small set of other nodes, which are diffused across the network. In classical PBFT-like protocols, selected validator needs to hear from a vast set of nodes that comprise the network to come to a decision, despite adversary participants. On the other hand, these protocols are deterministic, which means that the network agrees on a decision with absolute certainty.
In contrast, Nakamoto Consensus scales to many nodes, thanks to redefinition of the classical problem of achieving safety with certainty and making it probabilistic. Each new block added to the longest chain drops the chance of reorganization exponentially and asymptotically approaches certainty. The main drawback of this design is that it takes a long time to make the user feel confident enough in transaction's finality. This makes Nakamoto Consensus too slow for applications such as p2p payments and Decentralized Finance.
Avalanche Consensus combines the best of these two approaches and proves that classical protocols can be generalized to behave probabilistically which significantly improves their performance compared to their deterministic counterparts. Safety of this protocol is guaranteed through metastability, meaning that it is designed to tip away from the balance, quickly favoring majority opinion over the other. It can also finalize all transactions almost immediately (on average under a second), as it inherits this property from classical consensus. On the other hand, like in Nakamoto Consensus, there is no known limit of the validator set size that can participate in the network, contrary to classical protocols whose performance degrades exponentially with greater participation. This is because classical protocols need O(n^2) messages to reach consensus, while in Avalanche no matter how many validators there are in the network they can agree on the next state transition in O(1) of messages per node (in constant time).
The voting process in Avalanche Consensus is what makes it unique, which is more like polling a gossiping population than actual voting. Validators are completely independent and there is no leader election. Each node determines whether it should accept a block and how likely it is to be in consensus with the rest of the network. Once a node sees high probability of agreement across the network, it locks in the vote and accepts transaction as final.
The technique used for making this decision is called Repeated Random Subsampling. A validator randomly selects without replacement other validators with stake-weighted probability to query them for opinion, over and over again, each time on a new randomly sampled set of nodes, until it builds up enough data to reach probabilistic confidence. Upon every successful query, the node increments its confidence counter for the queried choice and flips the choice once the confidence in its current choice becomes lower than the confidence of the new choice. This procedure continues for at least set amount of rounds or until sufficient confidence threshold is reached, afterwards the decision is finalized.
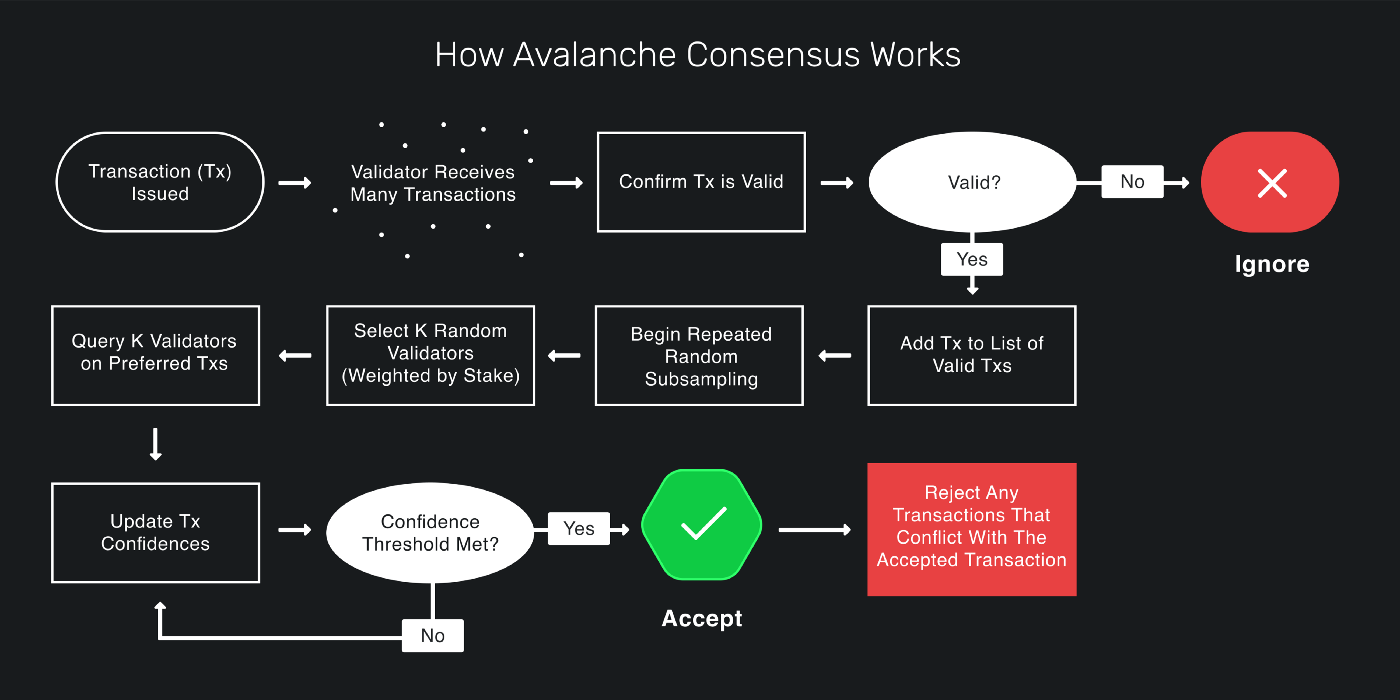
Avalanche Consensus is based upon a Snow family of binary BFT protocols derived from a non-BFT protocol called Slush, which incrementally builds up to Snowflake and Snowball BFT protocols. Slush introduces metastability through gossiping (subsampling), Snowflake adds Byzantine Fault Tolerance, and Snowball improves upon it with confidence counter memory. The Snow family of consensus protocols is more efficient when the fraction of Byzantine nodes is small, but it could be parametrized to tolerate more than a third of malicious nodes, by trading off liveness. Avalanche Consensus is comprised of multiple rounds of Snowball protocol. More specifically the consensus for the X-chain Directed Acyclic Graph (DAG) is called Avalanche, and for the linear P- and C- chains it is called Snowman, the difference being only in the underlying data structure.
In Avalanche network, each node implements an event-driven state machine, where when a node discovers a transaction by quering other nodes, it will start a one-time query process by sampling random peers and sending a message to them. Each node can answer the query by checking if the transaction is preferred among competing transactions. If every single ancestor of the block being currently voted on fulfills this criterion, the transaction is said to be strongly-preferred and receives a yes vote. Avalanche strictly assumes majority correctness, as the consensus always arrives at the outcome that the majority supports. The individual nodes are forced to flip their initial decision if they got convinced by the majority of the nodes to do so. Through combination of its properties, Avalanche achieves very fast finality and strong irreversibility properties.
In a cryptocurrency setting, cryptographic signatures enforce that only the key owner is able to create a transaction that spends a particular coin. Since correct clients follow the protocol as prescribed and never double spend their coins, in Avalanche, they are guaranteed both safety and liveness. In contrast, liveness is not guaranteed for rogue transactions, submitted by Byzantine clients, which conflict with the majority. Such decisions may stall in the network, but have no impact on safety of honest (majority) transactions. The Avalanche whitepaper concludes that this is a sensible tradeoff, and that the resulting system is sufficient for building complex payment systems.
Thanks to the unique design of its consensus algorithm, Avalanche can scale to very large number of validator nodes, possibly increasing the decentralization of block production. On the other hand, Avalanche can currently run cheaper transactions thanks to recently starting from zero state. Eventually Avalanche's state will catch up and run into similar scalability bottlenecks as Ethereum did in the past, as those lie out of reach of consensus-based improvements.
In PoS system, the nothing-at-stake attack is possible, where miners are incentivized to extend every potential fork. This causes rational miners to mine each of the forks to increase the likelihood of getting their block in the right chain. One way of dealing with this is to introduce a penalty mechanism: a miner producing on different forks is penalized by having part of their stake taken. Avalanche Consensus is by design non-forkable, and as such this kind of attack is mitigated by default. On the other hand this design doesn't allow the full nodes to fork away in case they decide that the majority correctness assumption got broken. While the longest chain rule based networks can return back to the valid chain and nullify the incorrect transactions done during the attack on the network, this is not possible on Avalanche, as once a block is finalized it is strongly irreversible.
As the consensus is leaderless, slashing for malicious behavior can't be implemented. Only weak incentives of PoS system are applied here, such as potential opportunity cost of no rewards for staked capital and costs of running the node. It could be argued that without strong incentive for behaving correctly, the fear of being slashed, the nodes have less incentive to stay honest, and so the majority honest assumption has higher probability of being broken. If the economic penalty for collusion is not maximized, then it is cheap to attack the system, regardless of the number of validators, especially when the stake in PoS systems is concentrated at the top. However, lack of slashing in Avalanche Consensus did not show any problems as of yet.
Disclaimer to the above discussion:
Recently upgraded and currently running version of the Snowman Consensus is called Snowman++ and has slight differences to its predecessor discussed in this article. It has been designed to fight contention on block proposals causing slowdown of time to finality (e.g. caused by MEV), as too much sampling occurred with too many proposals at the same time. The difference between Snowman++ and Snowman, is that for each new block 6 "preferred" block proposers are selected. Their proposals are then voted on as usual in Snowman protocol. These selected proposers have a time frame to propose a block, if none of them do, or if no proposal passes, the fallback is standard Snowman.
As explained by Emin Gün Sirer, Founder and CEO of Ava Labs:
The designated proposer is strictly a performance optimization. *Anyone* can fill the same slot without electing a new leader, though if the designated proposer is alive and fast, it has priority.
Due to lack of a more formal description of the updated protocol mechanisms, we don’t discuss its influence on the overall Avalanche blockchain performance here.
4. Data Availability
After explaining the design of Avalanche Consensus and how it strives to lead to increased decentralization through allowing many full nodes to participate, in this second part we discuss the approach of Celestia, focused on solving the Data Availablity (DA) problem.
Long-term, the most valuable asset of the blockchain stack is the blockspace, and the biggest obstacle for decentralized scaling of blockchains is usually assumed to not be the consensus algorithm, but the state growth (state bloat). This is because as the new blocks are added, the total information about all the past transactions grows and needs to be stored by each full node and computed over when validating new transactions. The block verification time increases together with the state size, as reading and updating the state from the storage root requires O(k log(n)) time, where n is the state size and k is the object access in the block. This also causes extensive syncing times for nodes. Not every user can afford the computing power to run a full node, its expensive, technically difficult and could take forever to sync one like on Ethereum network.
In 2017, Vitalik Buterin proposed the concept of stateless clients, discussing the importance of DA. The purpose of stateless clients is to introduce a light client type of node which does not require storing the total state of the entire blockchain to verify a block. This solution enables every user to become a full-fledged citizen of the network, and keeps the blockchain decentralized. As light clients require very few resources, they can run even on a smartphone, and through a special design called Data Availability Sampling (DAS), users can keep the validators in check. Each light node, can independently verify the broadcasted blocks and control that the stakers are not doing anything suspicious, while being able to reject the blocks if it concludes they shouldn’t be accepted. If enough nodes reject the block, the chain forks, the malicious validators are slashed and honest majority is restored.
4.1 State growth problem
To understand better how the state growth has been recognized as a bottleneck, let’s first go back in time and consider Bitcoin’s Segregated Witness (SegWit) soft fork. SegWit refers to a change in the Bitcoin's transaction format, removing the signature information from the input field of the block, storing it separately and charging a different (4x lower) weight units amount ("gas price") for the witness data with respect to the non-witness data. The upgrade's purpose was to decrease transaction times by increasing block capacity and so to speed up the validation process. More specifically, this solution enhances scalability by splitting signature data away from the UTXO (Unspent Transaction Output) set, which is the Bitcoin's "state". It is not the higher block size that is centralizing the network, but the higher required compute per state transition. SegWit is in a way a block size increase as it increases bandwidth/storage costs, but it doesn't increase maximum UTXO operations per block. This upgrade has been introduced to bound the rate at which the Bitcoin state grows, as it was recognized as the main bottleneck of the whole system. Post-SegWit, the maximum amount of non-witness data per block is unchanged, so the state growth is exactly the same, but overall, more data fits in the block due to the different witness-data pricing.
At this year’s ETH Dubai, Dankrad Feist, researcher at the Ethereum Foundation, has defined Data Availability to mean the permissionless ability to reconstruct the state. Most of the crypto community did not realize the importance of DA until recently, because classical Bitcoin security model is that everyone runs a full node that downloads every block, which implicitly guarantees DA. Unfortunately this simple approach cannot be scaled to high tps in a decentralized manner. Not all users can afford the full node, but they can run light clients, downloading only block headers and relying on fraud or validity proofs for confirming the correctness of the state transition. However, it is difficult to understand without downloading the whole block, if the data underlying this state transition is available.
Verifying the fraud proof involves processing the block to see if there is some error in the processing done by validators. If there is an error, this invalidates the block. The introduction of fraud proofs theoretically allows light clients to get close to full client equivalent, and to have the assurance that the blocks received by the client are not fraudulent. If a light client receives a block, it can ask the network for existence of any fraud proofs related to it, and if there are none, then after some time it can assume that the block is valid. While this mechanism is elegant, there is an important oversight here. What if an attacker creates a block, but does not publish all of the data? Fraud proofs are not a solution here, because hiding the data is not a uniquely attributable fault. Even if zero-knowledge proofs can verify block's correctness, missing data denies the other validators the ability to fully calculate the state or to create the blocks that interact with the portion of the state that is no longer accessible. Moreover, schemes such as hash locks for atomic cross-chain swaps, or coin-for-data trading, rely on the assumption that the data published to the blockchain will be publicly accessible and can fail when valid blocks with unpublished data are accepted.
4.2 Data Availability Sampling
Data Availability Sampling is proposed as the solution for proving the ability to reconstruct the state while avoiding the state bloat, and thus keeping high degree of decentralization. In short, by conducting the sampling process of the data extended through erasure coding, the light nodes give themselves assurance that the full original data is available.
To expand on this, and fully understand the issue, we remind here the two types of nodes that the blockchain node set can contain. Full nodes, are the nodes that download and verify the entire blockchain. Honest full nodes store and rebroadcast valid blocks that they have downloaded to other full nodes, and broadcast block headers associated with the valid blocks to the light nodes. Some of these nodes may participate in consensus by producing blocks. Light nodes, are the nodes with too low computational capacity and network bandwidth to download and verify the entire blockchain. They receive block headers from the full nodes, and on request, Merkle proofs that some transaction or state is a part of the block header.
The solution to this problem is best described by the authors of the original article introducing DAS, lead by Mustafa Al-Bassam, Co-founder and CEO of Celestia Labs:
A malicious block producer could prevent full nodes from generating fraud proofs by withholding the data needed to recompute the data root, and only releasing the block header to the network. The block producer could then only release the data - which may contain invalid transactions or state transitions - long after the block has been published and make the block invalid. This would cause a rollback of transactions on the ledger of future blocks. It is therefore necessary for light clients to have a level of assurance that the data matching the data root is indeed available to the network. We propose a data availability scheme based on the Reed-Solomon erasure coding where light clients request random shares of data to get high probability guarantees that all the data associated with the root of a Merkle tree is available. The scheme assumes there is a sufficient number o honest light clients making the same requests, such that the network can recover the data, as light clients upload these shares to full nodes, if a full node who does not have the complete data requests it. It is fundamental for light clients to have assurance that all the transaction data is available, because it is only necessary to withhold a few bytes to hide an invalid transaction in a block.
The DA problem is very subtle by nature because the only way to prove the absence of a transaction is to download all transactions, which is exactly what the light nodes want to avoid due to their resource restrictions. DAS relies on a long-existing data protection technique known as erasure coding, where a piece of data can be doubled in size to be fully recoverable from any 50% of this extended data. Adding redundant data allows for error correction and recovery in case of some part of the extended data are missing or being corrupted. By erasure coding blocks in a specific way, Celestia enables a resource-limited light node to randomly sample a number of fixed small-sized chunks of data from the block and achieve high probabilistic guarantee that all the other chunks have been made available to the network. This guarantee can be assured thanks to the large number of nodes participating in the sampling process. Through this mechanism, malicious consensus can no longer trick the light nodes into accepting a chain that full nodes have rejected. A key property of DAS is that the more sampling nodes there are, the same probabilistic availability guarantees can be provided for larger amounts of data, effectively allowing the increase of the block size (achieving higher tps), but without increasing the computational requirements for the participating nodes, and thus staying decentralized.
How does it work in practice? Let's see on the simplified example.
When light clients receive a block header, they randomly sample data-chunks from the Merkle tree that its data root represents, and only accept a block once it has received all of the shares requested. If an adversarial block producer makes more than 50% of the shares unavailable to make the full data unrecoverable, there is a 50% chance that a light node will randomly sample an unavailable share in the first draw, a 25% chance after two draws, a 12.5% chance after three draws, and so on (this is if they draw with replacement, in the full scheme they draw without replacement, so the probabilities from this example will be even lower). For this scheme to work, there has to be enough light clients sampling the shares, so that the block producers will be required to release more than 50% of the shares in order to pass the sampling challenge of all light clients, and so that the full block can be recovered.
To be even more detailed, standard Reed-Solomon encoding is insufficient and for Celestia's approach multi-dimensional encoding is used, reducing the cost to sample the data to O(n^(1/d)), where d is the number of the encoding dimensions. The original paper discusses it for d = 2, but it could be generalized to higher dimensions. This means that the cost is proportional to the square root of the block size. If a light client is sampling the data of a 1 MB block, it will be downloading 1 kB, if the block size is 1 TB, the download size would be 1 MB, and so on. The more users are doing the sampling, the bigger the block size can grow without imposing limits on decentralization. This sub-linear workload is the key feature of Celestia, first modular blockchain architecture, providing only DA and Consensus layers and having strong guarantees against validator collusion in the form of DAS.
(Note that the only significant advantage of the 2D Reed-Solomon scheme over the 1D scheme is smaller fraud proofs, so as in the future block headers coming with a zero-knowledge proof showing correct erasure coding may be required, this would remove the need for fraud proofs and the 2D scheme.)
4.3 Celestia
Celestia is not designed for maximizing the validator set, like we saw earlier in the case of Avalanche, rather it is designed to minimize the worst-case cost for someone to contribute security, and to maximize the cost to attempt to attack the system by slashing the block producers. When Celestia’s validators misbehave, not only full, but also light nodes can hold them accountable. While high resource requirements are assumed for block producers, they are kept very low for verifiers and so a highly decentralized, censorship-resistant network is formed. Thanks to the low requirements for light nodes, even smartphones can participate in the sampling process and contribute to the security and throughput of Celestia. In practical setting, it is expected that the number of sampling nodes will be correlated with user demand. This correlation is interesting as it will define Celestia's blockspace supply as a function of demand, which means that unlike monolithic chains, Celestia can offer stable low fees even as the user demand grows, at any level of demand. The block size could be adjusted through governance decision and a soft fork.
However, data sampling itself is not a Sybil-resistant process. Hence, there is no verifiable way to precisely determine the number of nodes sampling the network. Furthermore, since nodes that participate in the sampling cannot be explicitly rewarded by the protocol they have to rely on their own implicit incentives.

Data consumption being independent from the state growth of Celestia allows more efficient resource pricing for various kinds of decentralized applications, leaving the execution and settlement to other networks. DA layer only stores historical data, which is measured and paid in bytes, and all state execution is metered by rollups in their own independent units. Since diverse blockchain activities are subject to different fee markets, a spike of activity in one execution environment shouldn’t deteriorate user experience in another.
To allow for interoperability, blockchains have to engineer a way of verifying of what is happening on the other chain that has been bridged to. Even best in class protocols like Inter-Blockchain Communication (IBC) have to assume that any block received from the other chain and signed by majority of validators is valid, without re-executing any of the transactions. This means that any bridge is assuming that the validator set from the other side of the bridge is majority honest. If that chain would become malicious, it could steal the bridged funds from our chain.
If we extrapolate this to the world of hundreds of thousands of chains with highly variable security, it makes it quite difficult to be sure at all times that the bridged chain is currently secure. By posting the data to common DA layer of Celestia, rollups achieve shared security. This is in contrast to a Cosmos Zone or Avalanche Subnet, where security needs to be separately bootstrapped. With Celestia, one can launch a blockchain and inherit the shared security, improving on the vision of Cosmos for the Internet of Blockchains.
Currently with Ethereum-compatible rollups, the Ethereum chain is enshrined to the rollup as a settlement layer, making the rollups effectively its offspring, where the correct rollup chain is defined by a smart contract on Ethereum. It is similarly defined in the Polkadot parachain model, where the relay chain is enshrined as a settlement layer for parachains. Rollups using Celestia DA layer do not have an enshrined bridge between the rollup and any settlement layer, making execution and settlement decoupled. How can then Celestia rollups bridge to other chains? Celestia is built using the Cosmos SDK, so it has the native IBC functionality. Moreover, not having an enshrined settlement layer can actually open us to a broader design space for cross-chain bridges. However, the downside is that we are not able to bridge the native asset from Celestia to the rollups and back in a trust-minimized way, e.g. for use as collateral. This is possible between rollups and Ethereum, as the connected rollup smart contract exists on Layer 1, but because Celestia as a chain doesn’t have smart contract execution, the bridge can only be trust-minimized in one direction.
Sovereign rollup is a new rollup implementation, without the overhead of bootstrapping and maintaining its own consensus layer and validator set, and without being subordinate to the social consensus of an enshrined settlement layer which the rollup may or may not align with. This can empower sovereign communities to track and enforce socioeconomic value and agreements freely. Such design also gives developers more flexibility over their execution environment of choice, as they are not bound to the inefficiencies of a settlement layer that must process fraud or zero-knowledge proofs for their rollup.
4.4 Modular blockchains
Not only the Celestia Labs team envisions the modular approach to be the key to decentralized blockchain scalability. Ethereum community tends to believe the same, also considering dedicated DA layer, but with common settlement and enshrined rollups, that allow creating simpler bridges between them. Danksharding is a proposed Ethereum upgrade for implementing DAS as a scaling solution. While sharding is a priority of the Ethereum roadmap, Celestia has no plans for sharding its chain.

More recently, another big player on the blockchain scalability scene, Polygon, introduced its Avail solution applying the Consensus + Data Availability configuration, extendable with rollups. Together with the other DA schemes, such as zkPorter or StarkEx, an EVM-compatible settlement layer Cevmos, as well as many other distinct rollup solutions, notably Fuel - UTXO-based Optimistic Rollup (claiming to be the fastest modular execution layer); these innovations are expected to become building blocks of the future modular blockchain networks prioritizing flexibility and decentralization.
5. Conclusions
In the introduction we have defined the problem that this article aims to explain; how important is the consensus design and the data availability guarantee in scaling blockchain systems while keeping them decentralized. One is emphasized by Avalanche and the other by Celestia, so the features of these networks have been described in more detail as well. Through this comparison we can see that there is even some similarity between these different solutions, because of similar sampling-based technique for nodes reaching conclusions, allowing large numbers of nodes to participate in the process. Both approaches introduce new pros and cons while trying to improve over the older blockchain networks’ designs. While Avalanche lets more full nodes to participate in the block production, Celestia allows users to run light clients that on their own can verify the state of the chain with little resources. A major difference that arises from the directions chosen by each network is that while Avalanche Consensus is strongly irreversible and thus not forkable, Celestia actually priortizes forking away in case of the validator set being taken over by dishonest majority. The decision of which solution is better we leave to the reader and wish success to all the teams working hard on advancing the blockchain space, while not forgetting that our primary goal has always been decentralization.
Acknowledgements
Thanks to @0xomaryehia and @Jskybowen for checking the technical correctness of this article and providing very useful suggestions, @dirtydegen420 and @levels_crypto for confirming that it is clear enough for crypto-natives, an anon fren for ensuring it is approachable for technical but non-crypto native reader, and finally @nickwh8te and @kevinsekniqi and others, for their public discussions on twitter that pushed me to try to understand better these topics.
Further reading
The Complete Guide to Rollups, by Jon Charbonneau
Snow White: Robustly Reconfigurable Consensus and Applications to Provably Secure Proof of Stake, by Phil Daian, Rafael Pass, and Elaine Shi
Ouroboros: A Provably Secure Proof-of-Stake Blockchain Protocol, by Aggelos Kiayias et al.
Combining GHOST and Casper, by Vitalik Buterin et al.
Narwhal and Tusk: A DAG-based Mempool and Efficient BFT Consensus, by George Danezis et al.
Baxos: Backing off for Robust and Efficient Consensus, by Pasindu Tennage et al.
Proof of Availability & Retrieval in a Modular Blockchain Architecture, by Shir Cohen et al.
Sources:
Endgame, by Vitalik Buterin
Blockchains don’t scale. Not today, at least. But there’s hope., by Preethi Kasireddy
People confuse consensus algorithms vs. Sybil resistance mechanisms, by Preethi Kasireddy
How Does Distributed Consensus Work?, by Preethi Kasireddy
Understanding Blockchain Latency and Throughput, by Lefteris Kokoris-Kogias
From blockchain consensus back to Byzantine consensus, by Vincent Gramoli
Consensus in the Presence of Partial Synchrony, by Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer
SoK: Consensus in the Age of Blockchains, by Shehar Bano, et al.
Tendermint: Consensus without Mining, by Jae Kwon
What is Tendermint, by Interchain Foundation
Tendermint Explained — Bringing BFT-based PoS to the Public Blockchain Domain, by Chjango Unchained
Understanding the Basics of a Proof-of-Stake Security Model, by Interchain Foundation
Sentry Node Architecture Overview, by Jack Zampolin
Ignite (Tendermint) and The Cosmos Network, by Cryptopedia
Casper FFG: Consensus Protocol for the Realization of Proof-of-Stake, by Juin Chiu
Gasper, by Joshua Douglas
Consensus Compare: Casper vs. Tendermint, by Interchain Foundation
Snowflake to Avalanche, by Emin Gun Sirer
Demystifying “Snowflake to Avalanche”, by Mohamed ElSeidy
Scalable and Probabilistic Leaderless BFT Consensus through Metastability, by Team Rocket, et al.
Avalanche Blockchain Consensus, by Ava Labs
Avalanche Consensus 101, by Collin Cusce
Nakamoto (Bitcoin) vs. Snow (Avalanche): Consensus, by Gyuho Lee
Logan Jastremski Podcast #9: Kevin Sekniqi || Ava Labs: Blockchains from First Principles
Logan Jastremski Podcast #13: Kevin Sekniqi & Sreeram Kannan || Security models & Ethereum PoS
Inside the Avalanche ecosystem with Ava Labs' COO Kevin Sekniqi
Snowball BFT demo, by Ted Yin
The Ethereum Off-Chain Data Availability Landscape, by Aditi and John Adler
What is a modular blockchain?, by Nick White
Modular Blockchains Notes, by @ptrwtts
First Principles of Modular Blockchains, by Celestia Labs
Fraud and Data Availability Proofs: Detecting Invalid Blocks in Light Clients, by Mustafa Al-Bassam, Alberto Sonnino, Vitalik Buterin, and Ismail Khoffi
A note on data availability and erasure coding, by Vitalik Buterin
Focus on the data availability layer to understand the new public chain Celestia, by CoinYuppie
Celestia: Turning Modularity Into Reality, by Zainab Hasan
Pay Attention To Celestia, by Can Gurel
Logan Jastremski Podcast #11: Nick White || COO of Celestia Labs: Modular Blockchains
Rollups as Sovereign Chains, by Mustafa Al-Bassam, Ertem Nusret Tas, and Nima Vaziri
Ethereum & Celestia: Designing Modular Stacks: Jon Charbonneau hosts John Adler and Dankrad Feist
Modular Summit 2022: Modular or Monolithic - Mustafa Al-Bassam and Anatoly Yakovenko
What is danksharding?, by alchemy
Proto-Danksharding FAQ, by Vitalik Buterin
Stateless Clients: The Concept Behind, by Rabia Fatima
A state expiry and statelessness roadmap, by Vitalik Buterin
Thank you for the summary. It is very well written. I have come to the same conclusions reading most of this separately, and I find this accurate and digestible. I will point out that this focuses on the tech, and ignores other factors and economics that may influence adoption of any specific crypto. For example, the concentration of the initial or current allocation of any specific crypto. The ability to “fair launch” going forward for newer ones like Celestia.